12
ArchiveBox
source 오픈 소스 자체 호스팅 웹 아카이브.브라우저 기록 / 책갈피 / 포켓 / 핀 보드 등을 가져와 HTML, JS, PDF, 미디어 등을 저장합니다.
- 무료 앱
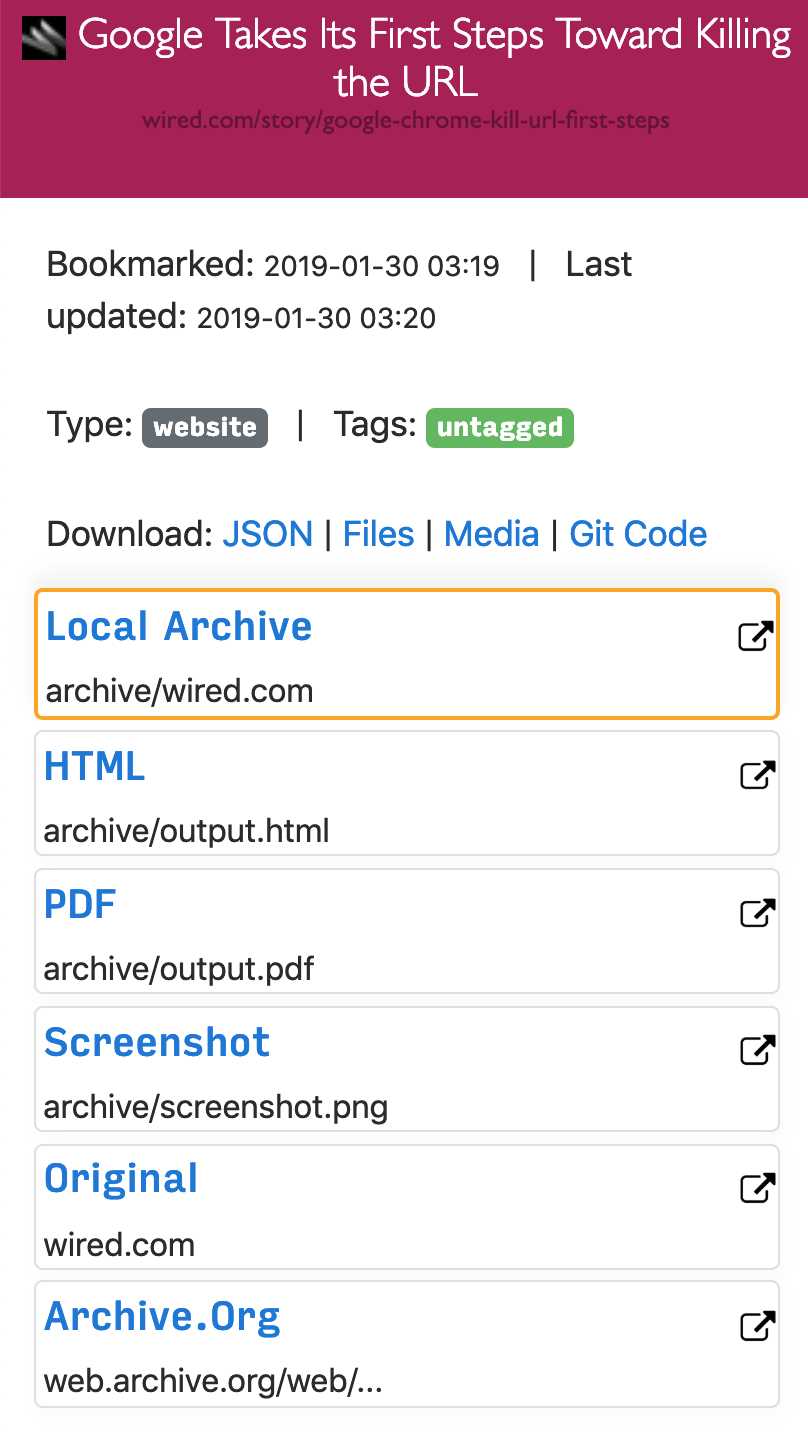
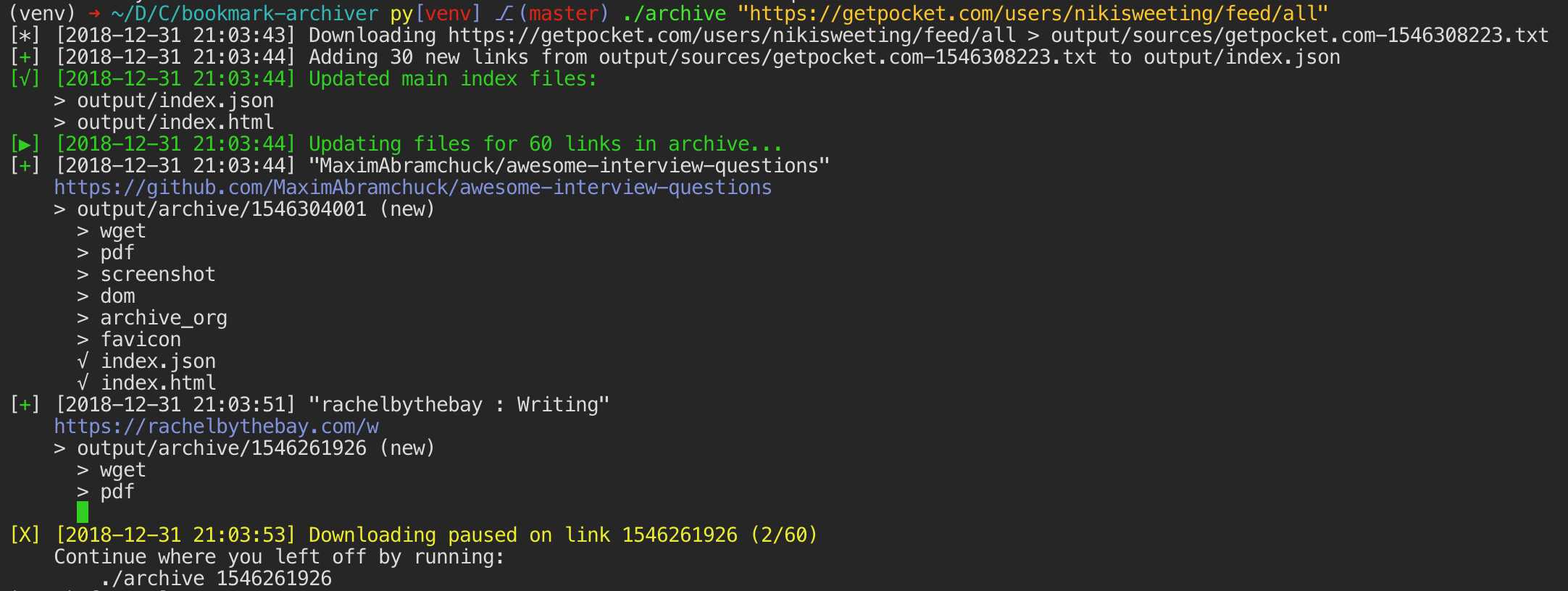
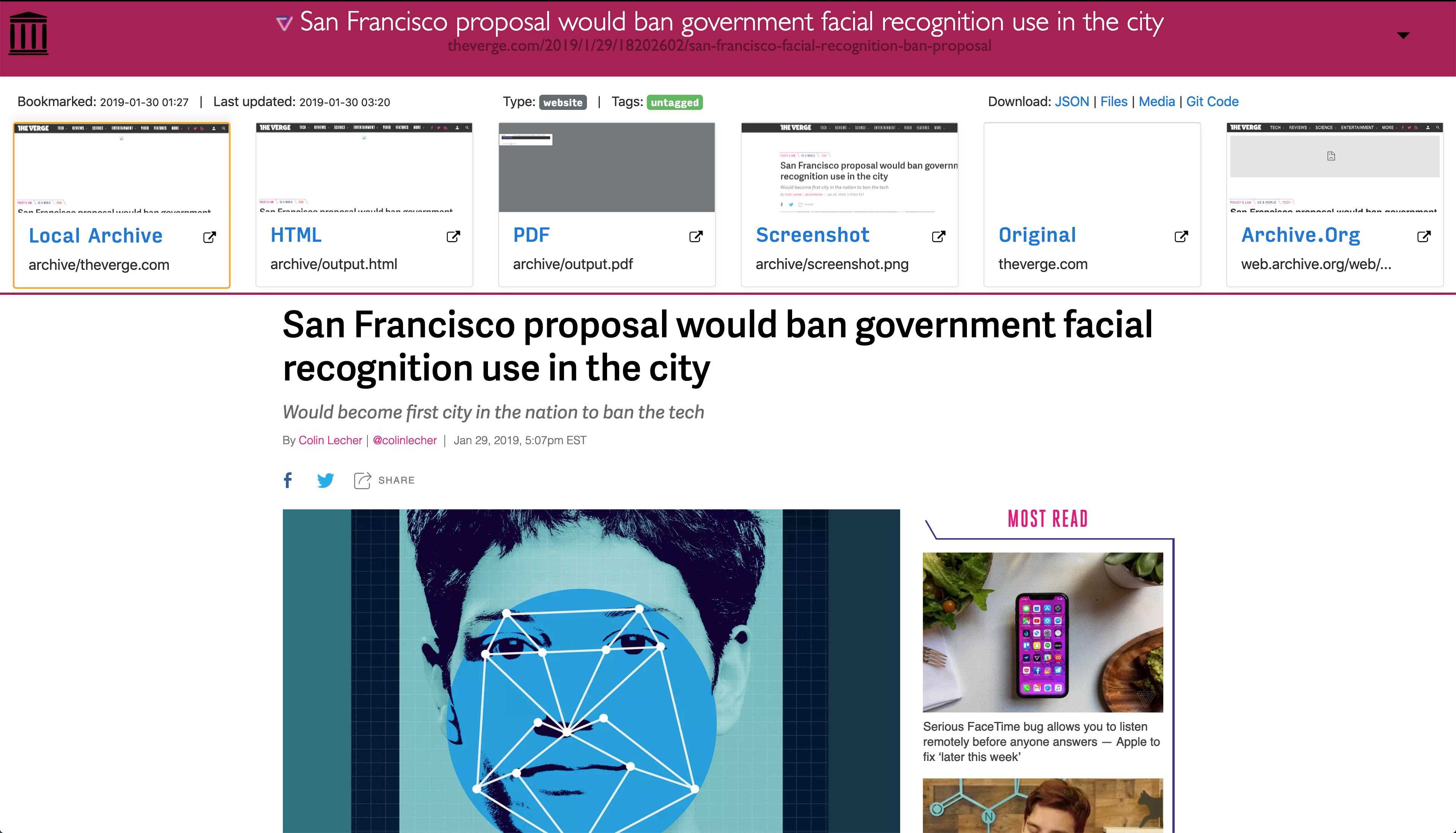
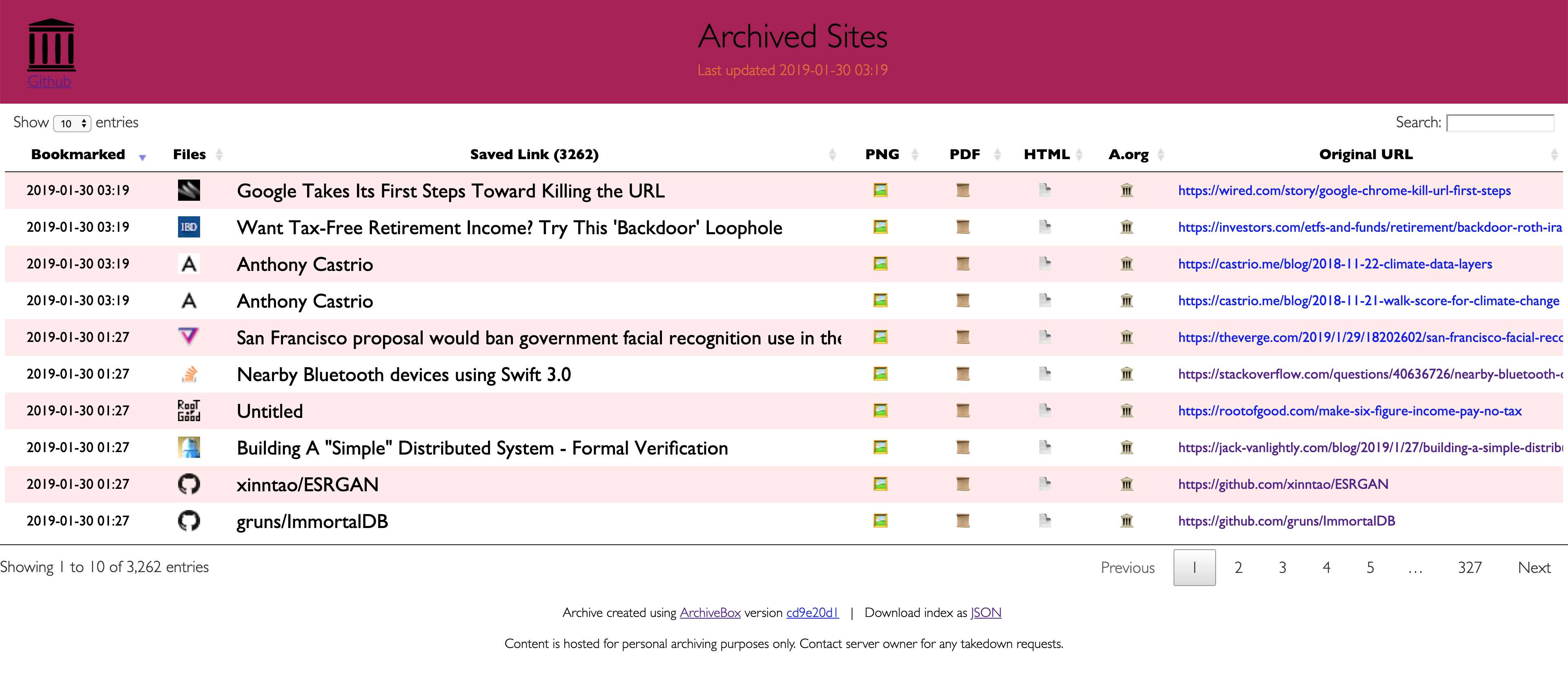
최신 웹 사이트는 복잡하고 종종 동적 컨텐트에 의존하기 때문에 ArchiveBox는 Archive.org 및 Archive.와 같은 공용 보관 서비스가 저장할 수있는 것 외에도 여러 가지 형식으로 사이트를 보관합니다.ArchiveBox는 stdin, 원격 URL 또는 파일에서 URL 목록을 가져온 다음 wget을 사용하여 찾아보기 가능한 HTML 복제본을 작성하고 youtube-dl을 사용하여 미디어를 추출하며 PDF를위한 Chromeless 헤드리스 전체 인스턴스를 사용하여 페이지를 로컬 보관 폴더에 추가합니다.스크린 샷 및 DOM 덤프 등 ... 여러 방법과 시장을 주도하는 브라우저를 사용하여 JS를 실행하면 가장 복잡하고 까다로운 웹 사이트도 최소한 몇 가지 고품질의 장기적인 데이터 형식으로 저장할 수 있습니다.###에서 링크를 가져올 수 있습니다 :-포켓, 핀 보드, Instapaper-RSS, XML, JSON 또는 일반 텍스트 목록-브라우저 기록 또는 북마크 (Chrome, Firefox, Safari, IE, Opera 등)-Shaarli, Delicious, Reddit저장된 게시물, Wallabag, Unmark.it 및 기타 링크가있는 텍스트!### 각 사이트에 대해 이러한 것들을 저장할 수 있습니다 :-`favicon.ico` 사이트의 파비콘-`example.com / page-name.html` 사이트의 복제본을 얻습니다. 존재하지 않으면 .html이 추가되어 출력됩니다.pdf` 헤드리스 크롬을 사용하여 사이트의 PDF 인쇄-`screenshot.png` 헤드리스 크롬을 사용하여 사이트의 1440x900 스크린 샷-`output.html` 헤드리스 크롬을 사용하여 렌더링 한 후 HTML 덤프-`archive.org.txt`archive.org에 저장된 사이트-html + gzipped warc 파일의 경우`warc /`.gz-`media /`youtube-dl을 사용하여 찾은 mp4, mp3, 자막 및 메타 데이터-github, bitbucket 또는 gitlab 링크에 대한 저장소의`git /`복제본-`index.html` &`index.json`메타 데이터 및 세부 정보가 포함 된 HTML 및 JSON 인덱스 파일 아카이브는 추가 적이므로 정기적으로 실행하고 인덱스로 새 링크를 가져 오도록`. / archive`를 예약 할 수 있습니다.저장된 모든 컨텐츠는 정적이며 JSON 파일로 색인화되므로 영원히 살 수 있고 쉽게 구문 분석 할 수 있으며 항상 실행되는 백엔드가 필요하지 않습니다.
카테고리
라이센스가있는 모든 플랫폼에서 ArchiveBox를 대체
2
WebArchives
웹 아카이브 뷰어는 Wikipedia 또는 Wikisource와 같은 대규모 커뮤니티 프로젝트에서 수백만 개의 기사를 오프라인으로 탐색 할 수있는 기능을 제공합니다.
1