9
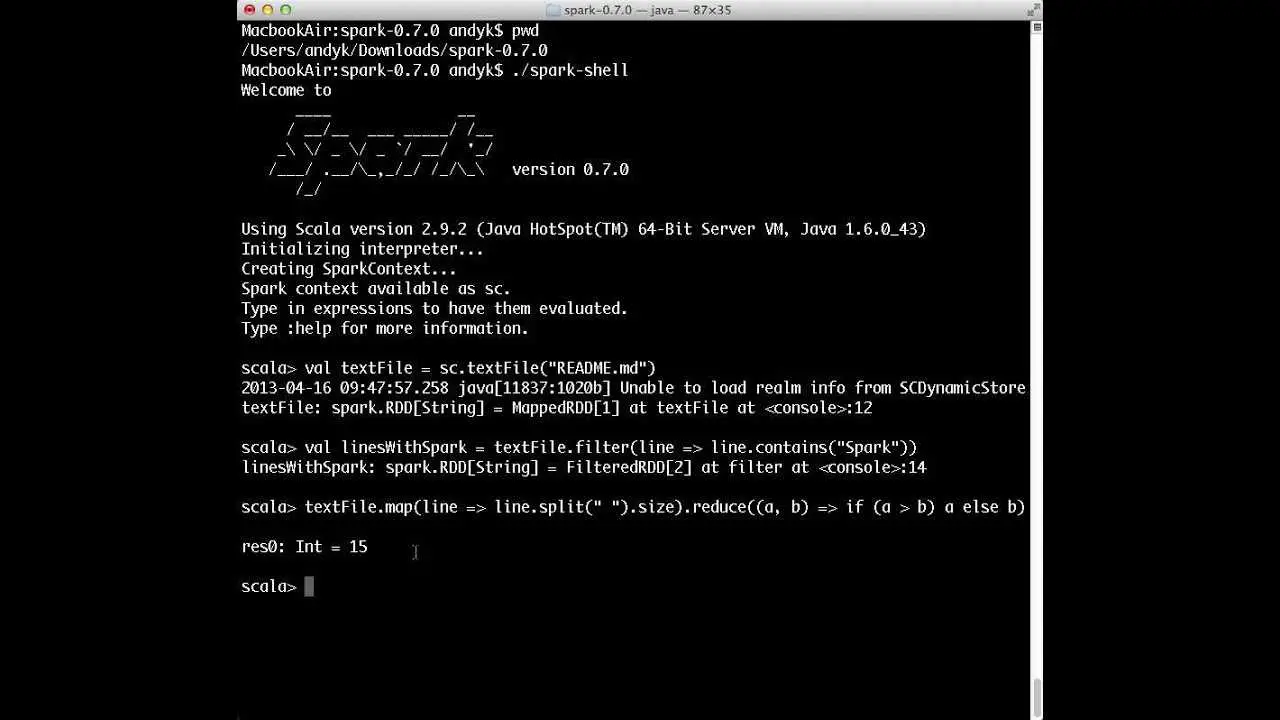
Apache Spark ™는 대규모 데이터 처리를위한 빠르고 일반적인 엔진입니다.속도 메모리에서 Hadoop MapReduce보다 최대 100 배, 디스크에서 10 배 빠른 프로그램 실행Spark에는 주기적 데이터 흐름과 인 메모리 컴퓨팅을 지원하는 고급 DAG 실행 엔진이 있습니다.
웹 사이트:
http://spark.apache.org카테고리
Linux 용 Apache Spark의 대안
18
Apache Hadoop
Apache Hadoop은 Apache v2 라이센스에 따라 라이센스가 부여 된 데이터 집약적 인 분산 애플리케이션을 지원하는 오픈 소스 소프트웨어 프레임 워크입니다.
1
Disco MapReduce
Disco는 MapReduce 패러다임을 기반으로하고 Python으로 작성된 분산 컴퓨팅을위한 경량의 오픈 소스 프레임 워크입니다.